Clustered DATA ONTAP Concepts
Clustered DATA ONTAP Concepts Clustered DATA ONTAP Concepts
In clustered Data ONTAP, all data access goes through a logical construct called a storage virtual machine (SVM). (This was previously referred to as a Vserver, and you’ll notice that the CLI still uses the older term.) As a result, the physical resources used by an SVM can change without necessitating any client-side or host-side changes or disruptions. Clustered DATA ONTAP Concepts
An SVM is a secure, virtualized storage container that includes its own administration security, IP addresses, and namespace. An SVM can include volumes residing on any node in the cluster, and you can have from one to hundreds of SVMs in a single cluster. Each SVM enables one or more SAN (FC, FCoE, iSCSI) and/or NAS (NFS, pNFS, CIFS) access protocols and contains at least one volume and at least one logical interface, or LIF. (See the following section for more on LIFs.)
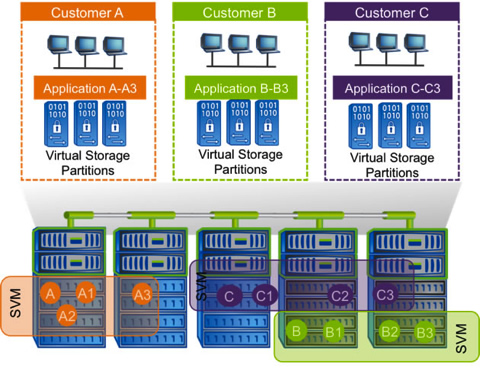
Figure 1) Clustered Data ONTAP uses storage virtual machines to separate logical entities from physical hardware and provide secure multi-tenancy.
You can have multiple SVMs within a cluster to serve different purposes. For instance, a service provider might use a separate SVM for each client on a cluster. SVMs are an import factor to consider when designing clustered Data ONTAP systems even if the environment they are going into isn’t inherently multi-tenant.
For instance, I prefer to keep storage volumes used by servers on one SVM and user share volumes on a separate SVM. I usually create all of my iSCSI/FC LUNs and NFS datastores/mounts in one SVM. I create CIFS shares in a separate SVM. This provides extra flexibility in case of disaster, similar to what you may be used to with the vFiler® unit dr command in 7-Mode.
Here are some other considerations when setting up SVMs. Clustered DATA ONTAP Concepts
- QoS policies can be applied directly to an SVM. This can be extremely useful in service provider scenarios. However, be aware that you lose granularity in your QoS structure when you apply it at the SVM level. If you apply QoS to an SVM, you cannot apply a QoS policy on a particular volume within that SVM, so it may not be the best way to use QoS in every case.
- You can separate departments within a company, keeping data completely separate from other departments.
- Chargeback can be greatly simplified. You can easily tell how much each SVM utilizes.
- You can use separate SVMs for administrative purposes. You can give different groups or departments administrative rights to manage their own data without compromising other SVMs.
Netapp How to’s
Thanks for Your Wonderful Support and Encouragement
More than 40,000 techies are part of our ARKIT community. Join us today and keep learning Linux, Cloud, Storage, DevOps, and IT technologies.





