understanding about volume and aggregate reallocation
Understanding about volume and aggregate reallocation
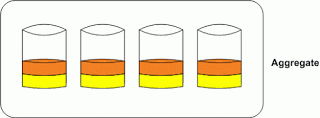
understanding about volume and aggregate reallocation, one of the most misunderstood topics I have seen with NetApp FAS systems is reallocation. There are two types of reallocation that can be run on these systems; one for files and volumes and another for aggregates. The process is run in the background, and although the goal is to optimize placement of data blocks both serve a different purpose. Below is a picture of a 4 disk aggregate with 2 volumes, one orange and one yellow.
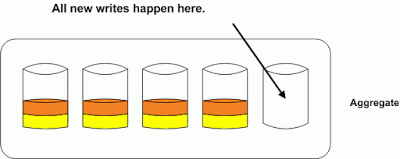
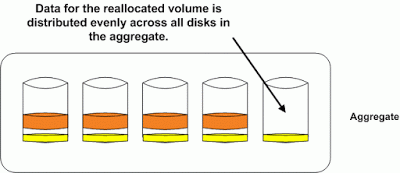
Now if we run a volume reallocation on the yellow volume the data will be spread out across all the disks in the aggregate. The orange volume is still unoptimized and will suffer from the hot disk syndrome until we run a reallocation on it as well.
The other big area of confusion is what an aggregate reallocation actually does. Aggregate reallocation “reallocate -A” will only optimize free space in the aggregate. This will help your system with writes as the easier it is to find contiguous free space the more efficient those operations will be. Take the diagram below as an example of an aggregate that could benefit from reallocation.
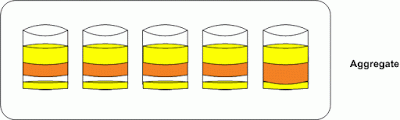
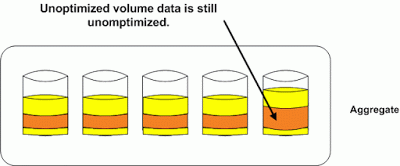
We still have the unoptimized data from the volume we did not reallocate. The only thing the aggregate reallocate did was make the free space in it more contiguous for writing new data. It is easy to see how one could be confused by these similar but different processes, and I hope this helps explain how and why you would use the different types of reallocation.
The smallest addressable block of data in Data ONTAP is 4k. However, all data is written to volumes in 256k chunks. When data block which is bigger than 256k comes in, filer searches for contiguous 256k of free space in the file system. If it’s found, data block is written into it, if not then filer splits the data block and puts it in several places. It’s called fragmentation and is familiar to everyone from the times, when FAT files ystems were in use. It’s not a big issue in modern file systems, like NTFS or WAFL, but defragmentation can help to solve performance problems in some situations.
In mostly random read/write environments (which is quite common these days) fragmentation has no impact on performance. If you write or read data from random places of the hard drive it doesn’t matter if this data is random or sequential on the physical media. NetApp recommends to consider defragmentation for the applications with sequential read type of workload:
- Online transaction processing databases that perform large table scans
- E-mail systems that use database storage with verification processes
- Host-side backup of LUNs
Reallocation process uses thresholds values to represent the file system layout optimization level, where 4 is normal and everything bigger than 10 is not optimal.
To check the level of optimization for particular volume use:
> reallocate measure –o /vol/vol_name
If you decide to run reallocate on the volume, run:
> reallocate start –f /vol/vol_name
There are certain considerations if you’re using snapshots or deduplication on volumes. There is a “-p” option, to prevent inflating snapshots during reallocate. And from version 8.1 Data ONTAP also supports reallocation of deduplicated volumes.
Conclusion
When we add an disk to aggregate we have to reallocate the volumes to distribute the blocks. When we create volume and expanding volume better to run reallocation process to get good performance always.
Thanks for your wonderful Support and Encouragement